



Subscribe to Bankless or sign in
AI researchers have hit a "data wall," where publicly available internet data is no longer enough for large-scale model training.
In response, tech giants are increasingly buying private data, netting platforms like Reddit hundreds of millions annually from selling user-generated content as training material. Photobucket, Tumblr, and Stack Overflow profit by licensing user data to AI developers, with the individuals whose content drives these advancements rarely receiving compensation. Shutterstock has inked deals valued between $25M and $50M to license its stock media libraries to AI companies, while Meta even considered acquiring Simon & Schuster for access to its e-book catalog.

This growing economic divide reflects a broader trend in which access to data is increasingly controlled by a few wealthy tech companies. This highlights a deeper issue: User data holds immense value, yet most see no return for what they create.
Vana was created to tackle this growing problem. As an upcoming EVM-compatible Layer 1 designed for collective ownership of user-contributed data, Vana’s blockchain allows users to pool their data in Data DAOs, empowering them to earn rewards and gain ownership in the AI models built from their contributions.
In this article, we’ll explore the upcoming L1’s architecture, key features, and the Data DAOs already building on top of the network that may fundamentally affect how AI is built and how users benefit from the value their data creates.
How  Vana Works and Its Architecture
Vana Works and Its Architecture
Vana’s blockchain is composed of three core layers: the Data Liquidity Layer, the Data Portability Layer, and the Connectome. Together, they form a robust foundation for Data DAOs to pool, validate, and monetize user-contributed data.
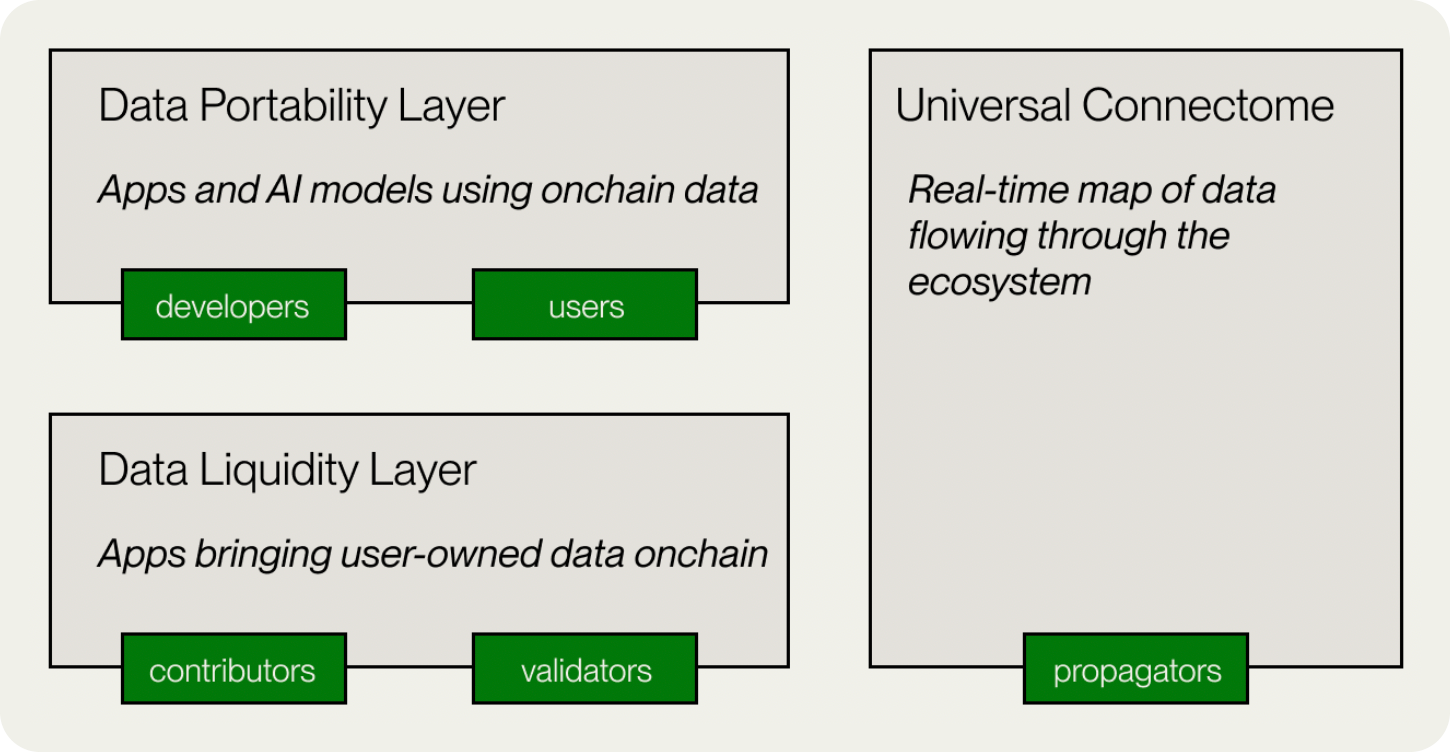
What is Vana’s blockchain? Vana’s blockchain is a proof-of-stake, EVM-compatible Layer 1 designed to enable collective ownership and monetization of user-contributed data through Data DAOs.
How do Data DAOs work on Vana’s blockchain? Data DAOs on Vana’s blockchain pool user-contributed data into liquidity pools, validate it using proof-of-contribution, and allow users to earn rewards and governance rights based on their data’s value.
1. Data Liquidity Layer
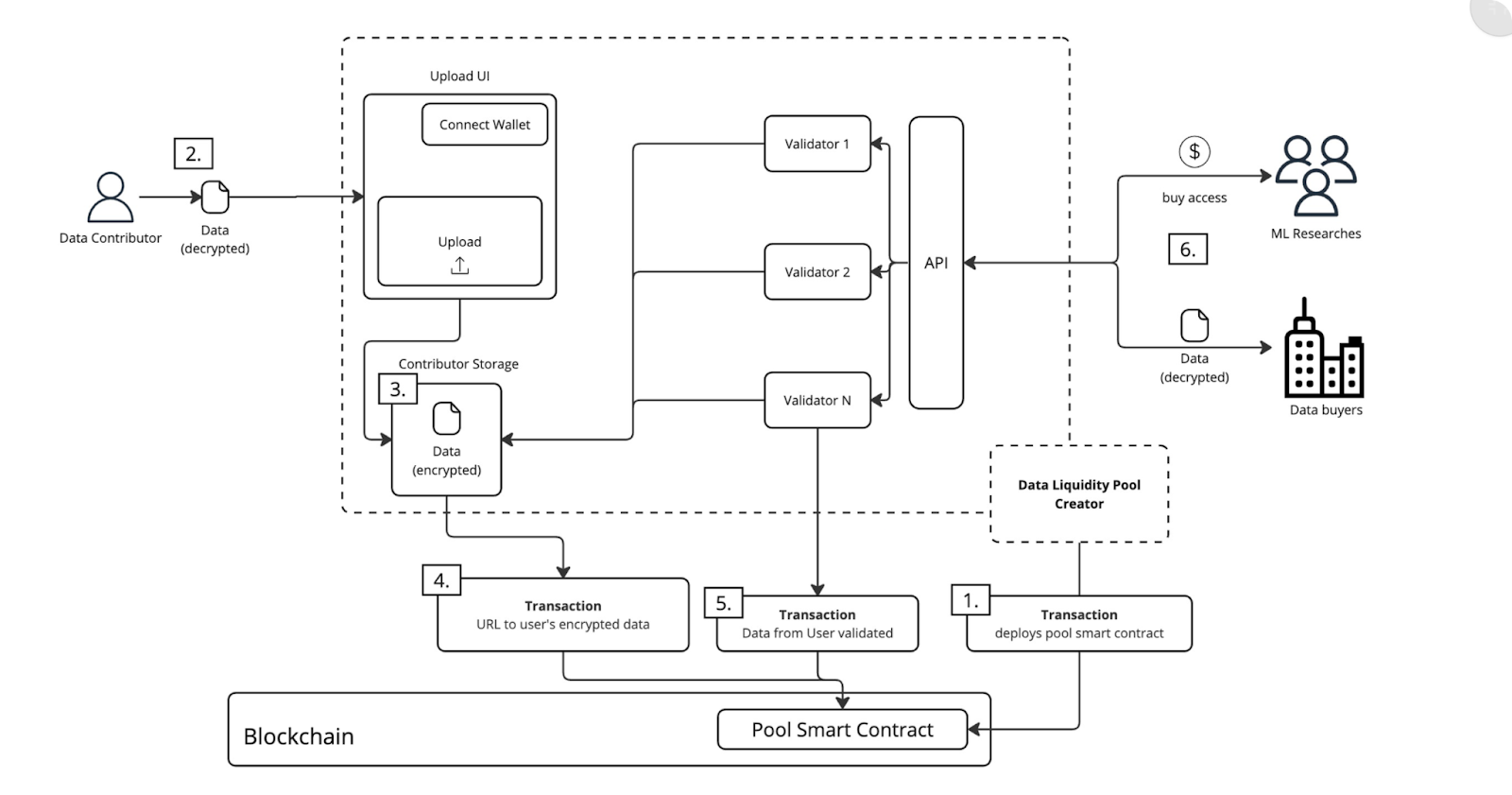
User-contributed data is pooled into Data Liquidity Pools (DLPs) on Vana’s blockchain.
Data is submitted through smart contracts and validated using Vana’s proof-of-contribution mechanism, ensuring that only high-quality data is accepted. Different Data DAOs can set their own quality parameters for proof-of-contribution, rewarding contributors based on the value of their data, like how much it improves an AI model. To further incentivize quality data, Vana rewards the top 16 DLPs chosen by VANA token holders, who are staking tokens on DLPs they expect to excel. The amount of VANA tokens staked determines the DLP ranking. This mechanism encourages competition among DLPs and ensures the highest-quality pools rise to the top.
While DLP creators can set the initial reward structure, governance eventually shifts to the community. DLP token holders and Data DAO contributors can vote on changes to the reward system and other operational aspects. A leaderboard tracks top DLPs, fostering transparency and healthy competition as newcomers challenge established pools with better data quality or more community support.
2. Data Portability Layer
The Data Portability Layer serves as the application layer of Vana’s blockchain, enabling developers and users to build dApps and AI models using pooled data.
It also provides a marketplace where contributors benefit from the value created by their data, depending on how the DAO decides to monetize it. For example, they could receive revenue from an AI model launched and governed by the Data DAO or by reselling the data to AI companies.

3. Connectome
At the core of Vana’s blockchain is the Connectome, a proof-of-stake, EVM-compatible ledger that records and validates real-time data transactions, ensuring Data DAOs can function across different ecosystems.
Enjoying this article?
Subscribe to Bankless or sign in
Each transaction includes essential metadata such as data type, format, properties, storage location, and attestations of validity. The Connectome tracks DLP token transfers, ensures cross-DLP data access, and supports user-owned applications. Since it is also EVM-compatible, Vana can be integrated with other blockchains and their applications.
Users retain full control over their encrypted data and keys but can delegate management to trusted Data Custodians, who securely store and protect user data, simplifying data management while maintaining privacy.
More transactions in the last 24h on Moksha (vana testnet), than on
— Anna Kazlauskas (@anna_kazlauskas) October 13, 2024Ethereum mainnet, Sepolia, and Base Sepolia
User-owned data is accelerating pic.twitter.com/wabtF1tVHu
Data DAOs Building on Vana
Despite being pre-mainnet, several early-stage Data DAOs have already sprung up on Vana’s blockchain:
🤖 r/datadao (Reddit Data)
The largest DAO currently, the r/datadao boasts data from 140K Reddit users, which have come together to train the first user-owned AI model, previously shown above, which it is currently integrating into a key feature on its homepage, and intends to launch with ORA as the world’s first Initial Model Offering (IMO). The DAO has also navigated and completed a sale of its data to an external AI company, the fruits of which it will distribute to members.
🐦 Volara (Twitter/X Data)
Volara, a Data DAO built by early  Bittensor miners, is focusing on Twitter/X data and utilizes Vana’s blockchain to enable contributors to own and monetize their social media content, providing researchers and developers access to valuable datasets while reducing traditional barriers to data availability.
Bittensor miners, is focusing on Twitter/X data and utilizes Vana’s blockchain to enable contributors to own and monetize their social media content, providing researchers and developers access to valuable datasets while reducing traditional barriers to data availability.
👔 DLP Labs (Resume Data)
DLP Labs’ Data DAO will allow users to monetize their resume data, aggregating data while ensuring contributors maintain ownership to build the largest contributor-owned resume dataset.
⛈️ Syd Intel (Threat Intelligence)
Syd is focused on decentralizing access to threat intelligence by aggregating data from Web2, Web3, and the dark web. Contributors can earn revenue by sharing threat intelligence data, such as whether an investor dumps tokens at TGE, if links are malicious or real, or if founders have a past history of rugging projects. All this data is then made accessible to security companies and developers on Vana.
🐷 DataPig (Trading Data)
DataPig aggregates trading data from DeFi platforms, providing personalized insights and trading analysis tools for users. The platform uses AI to analyze data, presenting it in an accessible, humorous format.
🧬 DNA DAO (Genetic Data)
Emerging in response to concerns over 23andMe’s potential sale of user data, as well as their previous leaks, DNA DAO (formerly 23andWE) looks to empower individuals to reclaim and control their genetic data with a DLP. By contributing to this collective, users safeguard their genetic information from corporate interests, ensuring it is shared ethically and transparently while having the option to contribute to research.
Closing Thoughts
Overall, Vana addresses one of the biggest challenges in AI development: data scarcity.
As AI models require larger, more diverse datasets, the value of user-generated data will grow. Vana’s solution — allowing users to collectively pool, verify, and monetize their data — creates a new paradigm for how data is used in AI and who is compensated. Data DAOs simultaneously provide a way for users to regain control of their data and share the value their data generates.
While the future is uncertain, Vana holds promise in addressing issues all parties in AI face, allowing for new design space that strengthens crypto’s role as a key player in the data economy.



