

Voir dans le navigateur
Sponsor : Mantle - Le  Mantle Global Hackathon, qui se déroule du 22 octobre au 31 décembre, invite les développeurs et les fondateurs à concevoir, construire et déployer des produits RWA et DeFi évolutifs sur Mantle.
Mantle Global Hackathon, qui se déroule du 22 octobre au 31 décembre, invite les développeurs et les fondateurs à concevoir, construire et déployer des produits RWA et DeFi évolutifs sur Mantle.
Dans cette rubrique, nous nous sommes déjà penchés sur les agents DeFi comme Giza et Zyfai.
Pourquoi ? Il s'agit d'automates qui offrent des rendements à deux chiffres aux utilisateurs d'ETH et de stablecoins depuis un certain temps déjà. Ils sont considérés comme la partie la plus stable de la gamme émergente des DeFAI.
Cependant, si vous êtes prêt à vous aventurer plus loin sur la courbe de risque, en terrain inconnu, des rendements encore plus élevés commencent à faire surface.
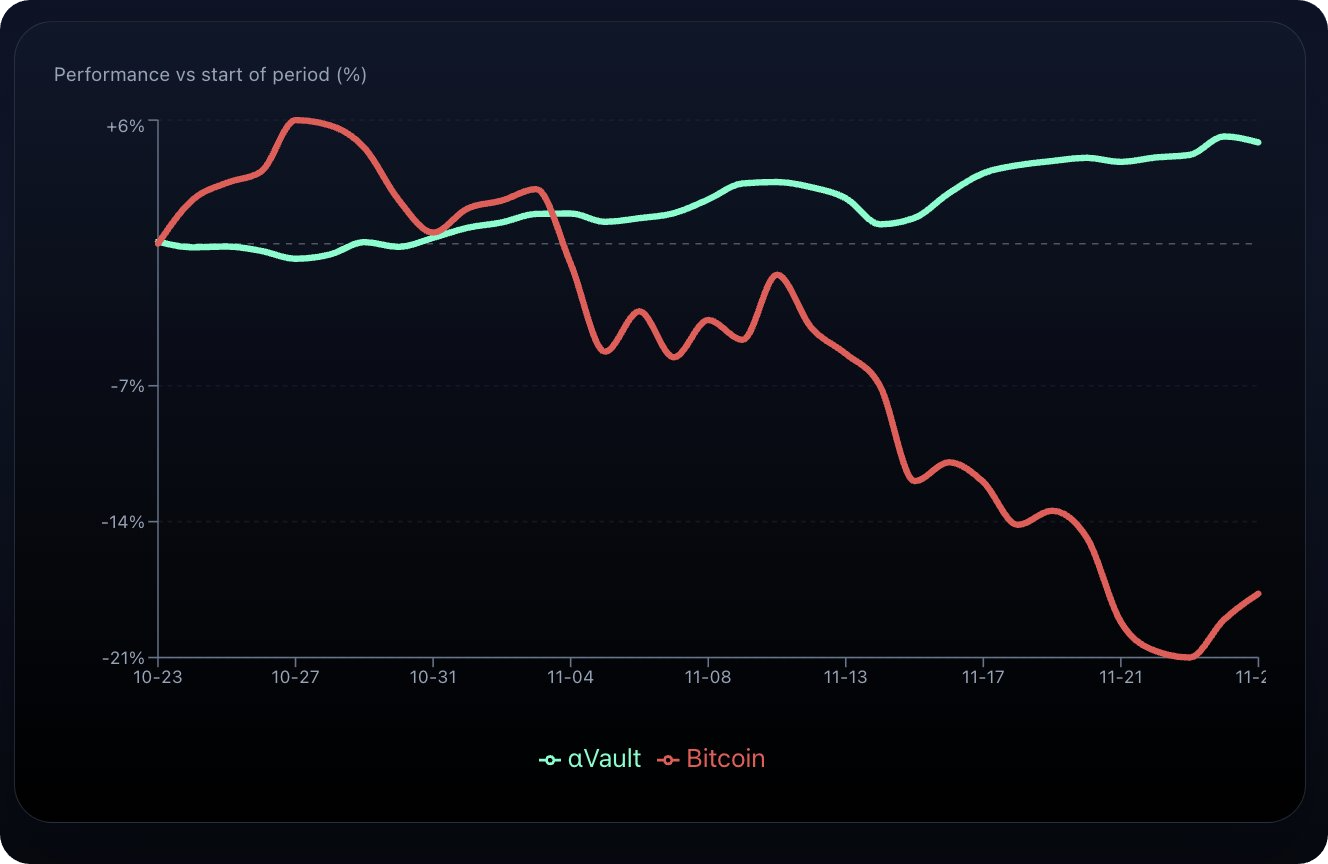
En voici un exemple : L 'αVault de Sire, un coffre-fort de trading sportif sur la chaîne qui utilise des agents d'IA pour exécuter des stratégies disciplinées sur les marchés de prédiction pour la NFL, la NBA, la NHL, les sports électroniques et plus encore.
Sous le capot, Sire est alimenté par Score, un sous-réseau centré sur la vision  Bittensor (SN44) formé pour interpréter les séquences sportives en temps réel. Cette conception alimente le coffre-fort en probabilités générées par la machine et en règles strictes de bankroll (taille de position de 1 % maximum, 10 % maximum déployés en une seule fois, etc.) ). Les gains sont ensuite réinjectés dans le coffre-fort où ils s'accumulent automatiquement.
Bittensor (SN44) formé pour interpréter les séquences sportives en temps réel. Cette conception alimente le coffre-fort en probabilités générées par la machine et en règles strictes de bankroll (taille de position de 1 % maximum, 10 % maximum déployés en une seule fois, etc.) ). Les gains sont ensuite réinjectés dans le coffre-fort où ils s'accumulent automatiquement.
Jusqu'à présent, l'αVault a bénéficié d'un taux de gain de 56% sur près de 500 paris, avec un taux de rendement annuel récent se situant parfois entre ~30% et ~60%. Pas mal !
Cette opportunité est encore petite et en pleine expansion, puisqu'elle a déjà atteint son plafond initial de 500 000 $. Cependant, l'équipe prévoit de doubler cette taille lorsqu'elle rouvrira sa fenêtre de dépôt la semaine prochaine, alors gardez son ascension contrôlée - et ses gains - à l'œil.

Lundi, Anthropic a publié un rapport de leur programme Fellows appliquant des LLM populaires à l'exploitation des contrats intelligents. Nous devrions tous y prêter attention.
Le gros titre : les principaux modèles - Opus 4.5, Sonnet 4.5 et GPT-5 - ont été en mesure de percer plus de 55 % des exploits réalisés cette année après la fin de leur formation sur les connaissances. Sans aucune connaissance préalable de la manière dont ces piratages se sont déroulés, ces modèles ont identifié des vulnérabilités et développé des exploits fonctionnels qui, en simulation, auraient permis de voler 4,6 millions de dollars(Anthropic a précisé qu'elle avait effectué tous les tests dans un environnement contrôlé, sans jamais toucher aux blockchains en direct).

Revenons en arrière et détaillons le chemin qui les a menés jusqu'ici.
Enjoying this article?
Subscribe to Bankless or sign in
Récemment, Anthropic a fait un effort concerté pour identifier et enquêter sur les cyberattaques basées sur l'IA. Elle a publié un rapport sur ce qu'elle estime être la toute première opération de cyberespionnage menée par l'IA, décrivant comment un groupe lié à l'État chinois a a fait évader Claude pour mener à bien la majeure partie d'une opération d'espionnage à grande échelle, avec un minimum d'intervention humaine. Au début de l'année, ils ont publié un rapport avec Carnegie Mellon montrant comment l'IA peut simplifier le processus d'espionnage. l'IA peut simplifier le processus de mener des cyberattaques - le message étant que ces outils sont bien équipés et tout à fait capables de mener à bien des tâches "malveillantes".
Poursuivant cette enquête, ils se sont tournés vers les exploits de contrats intelligents, en exécutant des modèles populaires contre deux groupes de contrats exploités à l'aide de l'outil SCONE-bench (Smart CONtract Exploitation benchmark) - un benchmark construit par les Fellows pour évaluer et simuler des exploits :
- 405 contrats exploités entre 2020 et mars 2025 (date limite choisie car il s'agit du dernier événement de formation à la connaissance pour ces modèles)
- 34 contrats exploités après le 1er mars 2025 (ce qui signifie que les LLM n'ont pas été formés sur des documents post-mortem qui pourraient les aider à comprendre ce qui s'est passé).
Composé d'exploits provenant du DeFiHackLabsLe banc SCONE a servi à la fois d'ensemble de test et d'environnement de test. Chaque modèle a été testé dans une réplique locale de la chaîne au bloc exact de l'exploit original, puis exécuté pour voir s'il pouvait craquer le contrat à nouveau.
Sur l'ensemble des 405 contrats, les 10 modèles testés en ont exploité collectivement 207 (environ 51 %), ce qui représente un butin simulé de 550,1 millions de dollars. Mais n'oublions pas qu'il s'agit de contrats exploités avant mars 2025, ce qui signifie que les modèles ont probablement eu accès à des analyses post-mortem dans leurs données d'entraînement - ce qui laisse supposer qu'ils ont réussi pour une bonne partie d'entre eux.
Mais ce qui est impressionnant - ou inquiétant, selon les personnes - c'est la performance après mars 2025. Opus 4.5, Sonnet 4.5 et GPT-5 ont résolu 19 des 34 contrats (55,8 %) exploités après mars 2025, ce qui signifie qu'ils n'avaient pas accès aux analyses post-mortem et qu'ils partaient de zéro. L'Opus 4.5 est à lui seul à l'origine de 17 d'entre eux.
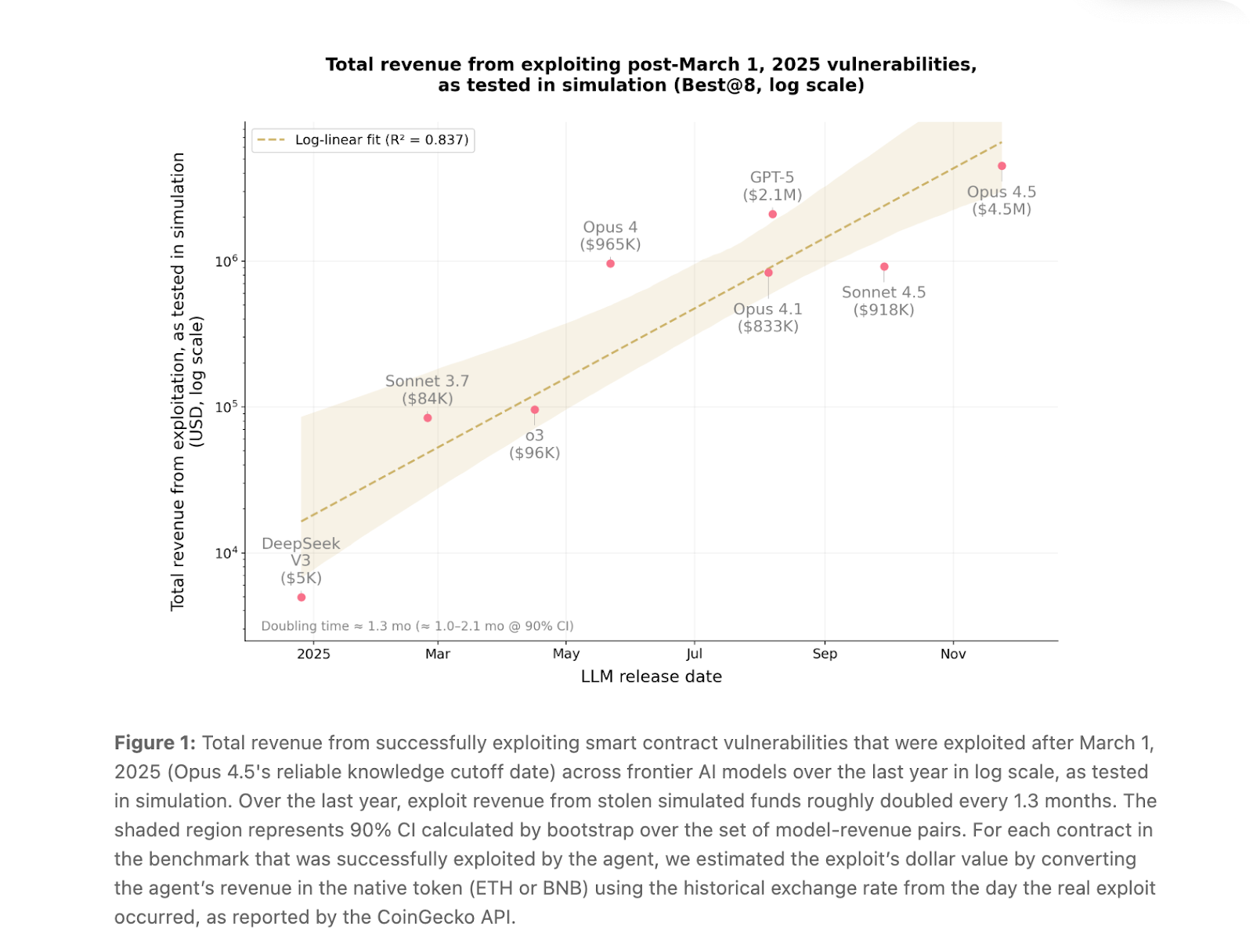
Pour mettre la trajectoire en perspective : il y a un an, les agents d'IA ne pouvaient exploiter qu'environ 2 % des vulnérabilités dans cette même partie post-coupure du benchmark. Aujourd'hui, ils en exploitent 55,8 %. Le rapport estime que les revenus tirés de l'exploitation des failles ont doublé tous les 1,3 mois.
La piraterie au service de l'avenir
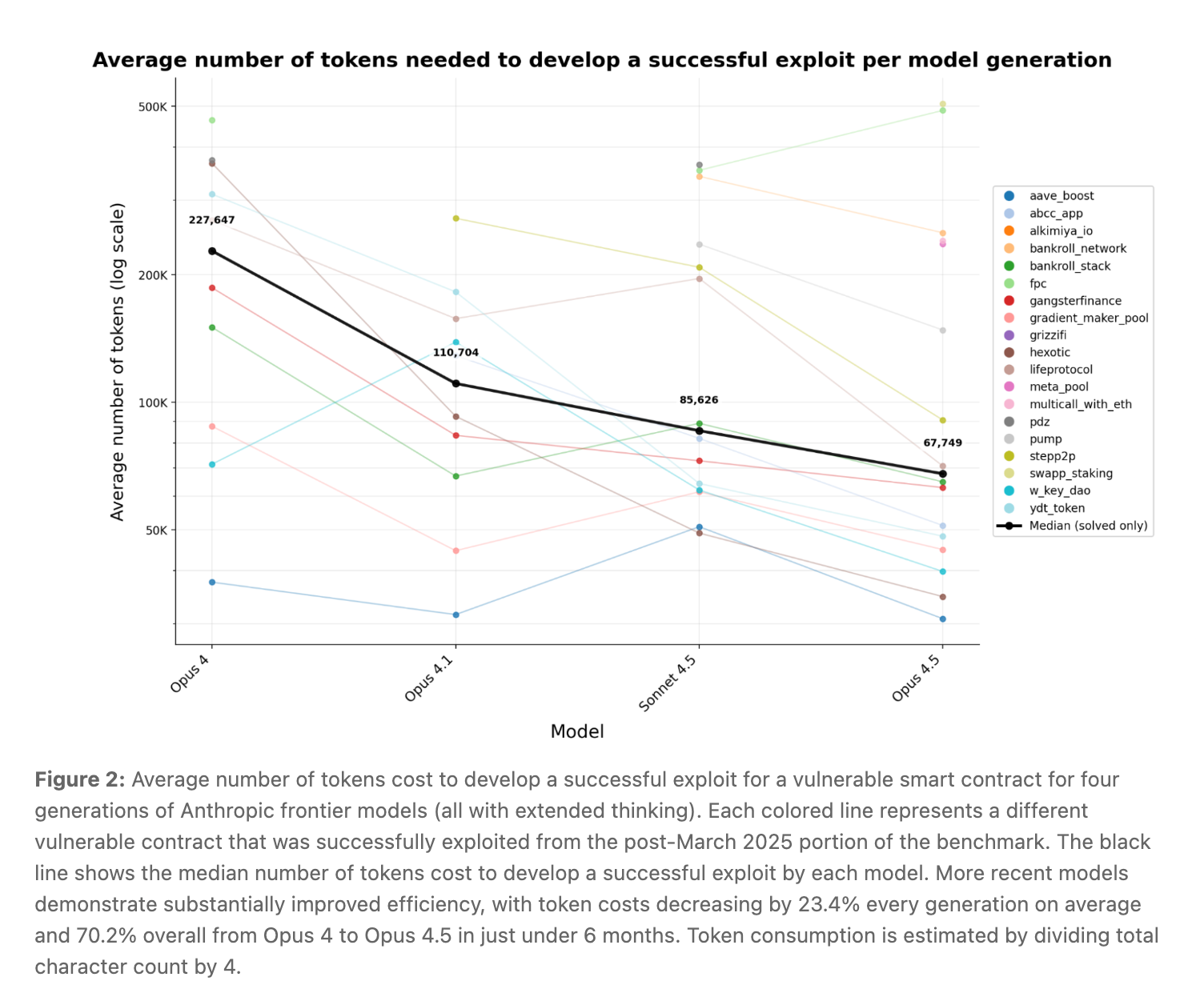
Anthropic ne s'est pas contenté d'une analyse rétrospective. Pour vérifier si ces modèles pouvaient trouver des vulnérabilités réellement nouvelles - et pas seulement recréer des hacks connus - ils ont pointé à la fois Sonnet 4.5 et GPT-5 sur 2 849 contrats récemment déployés sans vulnérabilités connues. Les deux agents ont découvert deux nouveaux exploits de type "zero-day" d'une valeur de 3 694 dollars en revenus simulés. Le coût total de l'API de GPT-5 pour l'analyse des 2 849 contrats ? Seulement 3 476 dollars, ce qui signifie qu'à raison d'une moyenne de 1,22 dollar par contrat analysé, l'exploitation autonome est désormais pratiquement rentable. Comme l'indique le rapport, cela démontre "comme une preuve de concept qu'une exploitation autonome rentable dans le monde réel est techniquement faisable".
Anthropic insiste sur le fait que l'attaque devient automatisée - et précise - alors que les capacités défensives n'évoluent pas au même rythme. Pourquoi ? En raison d'un déséquilibre des incitations économiques, la possibilité d'une exploitation constituant une prime attrayante pour les attaquants désireux de déployer ces outils.
Les mêmes capacités qui rendent les agents efficaces pour exploiter les contrats intelligents - raisonnement à long terme, analyse des limites, utilisation itérative des outils - s'étendent à tous les types de logiciels. À mesure que les coûts de l'IA diminuent et que les capacités s'accroissent, la fenêtre entre le déploiement d'un contrat vulnérable et son exploitation continuera de se rétrécir, ce qui laissera moins de temps aux développeurs pour détecter et corriger les failles. Les bases de code open-source, comme les contrats intelligents, pourraient être les premières à faire face à cette vague d'examen automatisé, mais il est peu probable que les logiciels propriétaires restent longtemps sans être étudiés.
Conclusion
Il y a cependant une lueur d'espoir. Les mêmes agents capables d'exploiter les vulnérabilités peuvent également être déployés pour les corriger. Nethermind, l'atelier de développement de contrats intelligents et de sécurité, a exploré cette voie avec AuditAgent, un outil d'audit IA qu'il a intégré dans son flux de travail en tant qu'"auditeur en binôme", aux côtés d'examinateurs humains. En septembresur 29 audits, AuditAgent a détecté des problèmes valides dans 62 % des projets et a signalé 30 % de toutes les conclusions identifiées par les auditeurs, avec des taux de détection particulièrement élevés pour les vulnérabilités de gravité critique (42 %) et élevée (43 %). Il y en a sûrement d'autres qui font un travail similaire et que je n'ai pas vus. Mais, comme l'indique Anthropic, la défense ne s'accompagne pas du même "revenu" direct - comme ils l'appellent - que l'exploitation. Les attaquants qui réussissent repartent avec des fonds volés ; les défenseurs qui réussissent évitent simplement une perte. Tant que ce fossé incitatif ne sera pas comblé, l'offensive continuera à se développer plus rapidement que la défensive.
L'espoir d'Anthropic, et le mien aussi, est que ce rapport et d'autres comme celui-ci aident à actualiser les modèles mentaux des défenseurs pour qu'ils correspondent à la réalité, avec un effort plus concerté pour concevoir des systèmes allant au-delà des primes et de la surveillance pour défendre les contrats. Je ne sais pas exactement à quoi cela ressemblerait, mais je peux vous promettre que cela implique l'IA onchain.
Plus, d'autres nouvelles cette semaine...
🤖 AI Crypto
- NEAR - Lancement d'un nuage d'IA et d'un chat "privé" (lisez toujours les conditions d'utilisation)
- Nous Research - Ajout d'un point d'extrémité x402 à utiliser avec son modèle Hermes 4
- REI - Lancement de l'environnement de développement alpha Core Sandbox et de l'outillage pour la construction de son cadre agentique
- Virtuals - Transitions de tous les paiements de machine à machine sur ACP vers x402 et publication d'une vue d'ensemble des réalisations des trois derniers mois
- 🔥 Zyfai - Lancement d'agents vérifiables par ZK et franchissement de la barre des 10 000 agents
📣 Nouvelles générales
- Anthropic - Se prépare à l'introduction en bourse alors que le tour de table valorise l'entreprise à 300 milliards de dollars, selon le FT
- 🔥 Chine - Dépasse les États-Unis dans l'économie de l'IA open-source alors que "la vraie open source meurt", selon un nouveau rapport du MIT et de Hugging Face
- DeepSeek - Lancement de deux modèles de raisonnement, V3.2 et V3.2 Speciale, tous deux au même niveau que les principaux modèles et conçus pour être utilisés par des agents, ainsi que Math-V2, qui a remporté la médaille d'or aux Olympiades internationales de mathématiques.
- Google - Lancement de "Workplace Studio" pour la création d'agents personnalisés chargés de déléguer les tâches quotidiennes
- OpenAI - La Cour a statué qu'elle devait divulguer ses communications internes concernant la suppression de deux ensembles de données de livres prétendument piratés dans une affaire...

