


Subscribe to Bankless or sign in
Los investigadores de IA se han topado con un "muro de datos": los datos de Internet disponibles públicamente ya no son suficientes para entrenar modelos a gran escala.
En respuesta, los gigantes tecnológicos compran cada vez más datos privados, lo que reporta a plataformas como Reddit cientos de millones al año por la venta de contenido generado por los usuarios como material de entrenamiento. Photobucket, Tumblr y Stack Overflow se benefician de la concesión de licencias de datos de usuarios a desarrolladores de IA, mientras que las personas cuyo contenido impulsa estos avances rara vez reciben una compensación. Shutterstock ha firmado acuerdos por valor de entre 25 y 50 millones de dólares para conceder licencias de sus bibliotecas multimedia a empresas de IA, mientras que Meta incluso se planteó adquirir Simon & Schuster para acceder a su catálogo de libros electrónicos.

Esta creciente brecha económica refleja una tendencia más amplia en la que el acceso a los datos está cada vez más controlado por unas pocas empresas tecnológicas ricas. Esto pone de relieve un problema más profundo: Los datos de los usuarios tienen un valor inmenso y, sin embargo, la mayoría no ve ningún retorno por lo que crean.
Vana se creó para hacer frente a este creciente problema. Como una próxima capa 1 compatible con EVM diseñada para la propiedad colectiva de los datos aportados por los usuarios, la blockchain de  Vana permite a los usuarios agrupar sus datos en Data DAOs, dándoles el poder de ganar recompensas y obtener la propiedad de los modelos de IA construidos a partir de sus contribuciones.
Vana permite a los usuarios agrupar sus datos en Data DAOs, dándoles el poder de ganar recompensas y obtener la propiedad de los modelos de IA construidos a partir de sus contribuciones.
En este artículo, exploraremos la arquitectura de la próxima L1, las características clave y las DAO de datos que ya se están construyendo sobre la red y que pueden afectar fundamentalmente a cómo se construye la IA y cómo los usuarios se benefician del valor que crean sus datos.
Cómo funciona Vana y su arquitectura
La blockchain de Vana se compone de tres capas principales: la Capa de Liquidez de Datos, la Capa de Portabilidad de Datos y el Connectome. Juntas, forman una base sólida para que las DAO de datos agrupen, validen y moneticen los datos aportados por los usuarios.
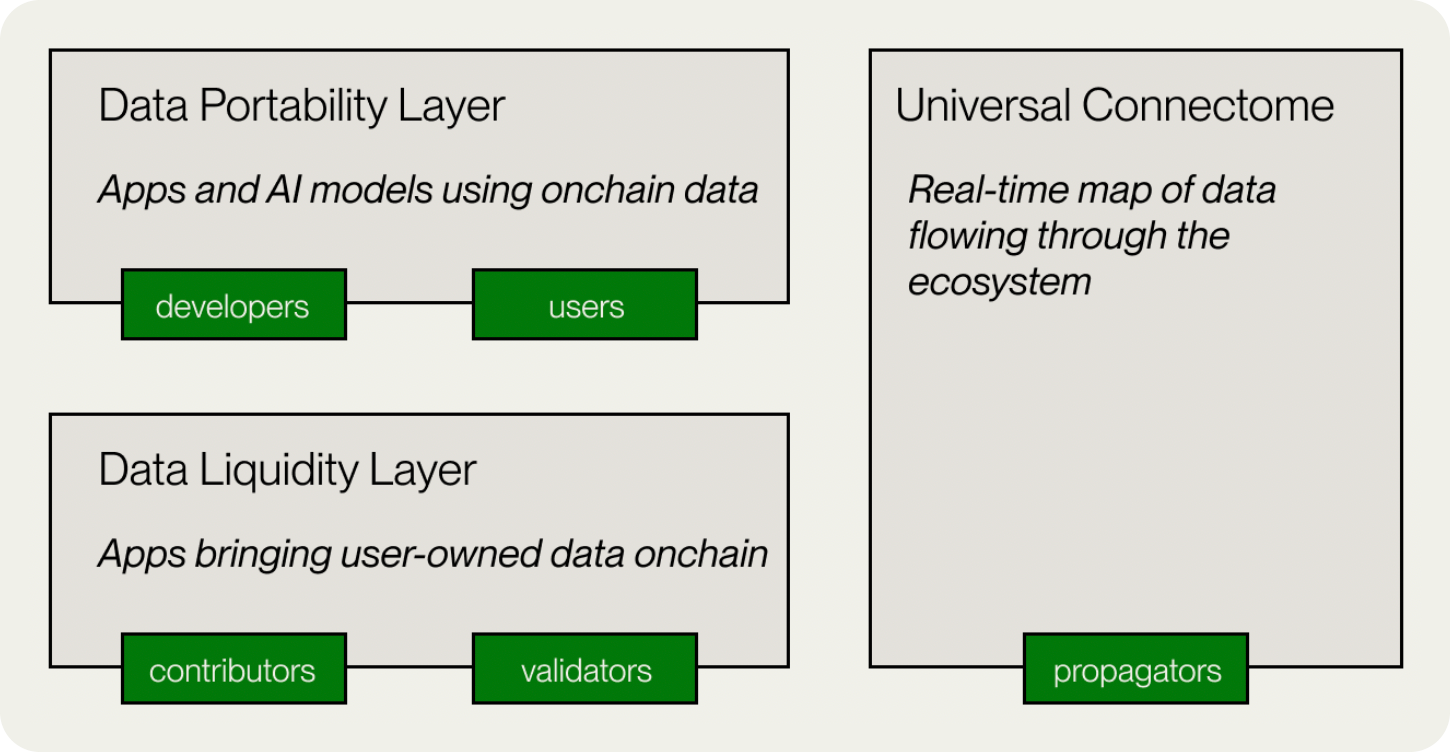
¿Qué es la cadena de bloques de Vana? La blockchain de Vana es una Layer 1 compatible con EVM y proof-of-stake diseñada para permitir la propiedad colectiva y la monetización de los datos aportados por los usuarios a través de Data DAOs.
¿Cómo funcionan los Data DAOs en la blockchain de Vana? Las DAO de datos en la blockchain de Vana reúnen los datos aportados por los usuarios en pools de liquidez, los validan mediante pruebas de contribución y permiten a los usuarios obtener recompensas y derechos de gobierno en función del valor de sus datos.
1. Capa-de-liquidez-de-datos
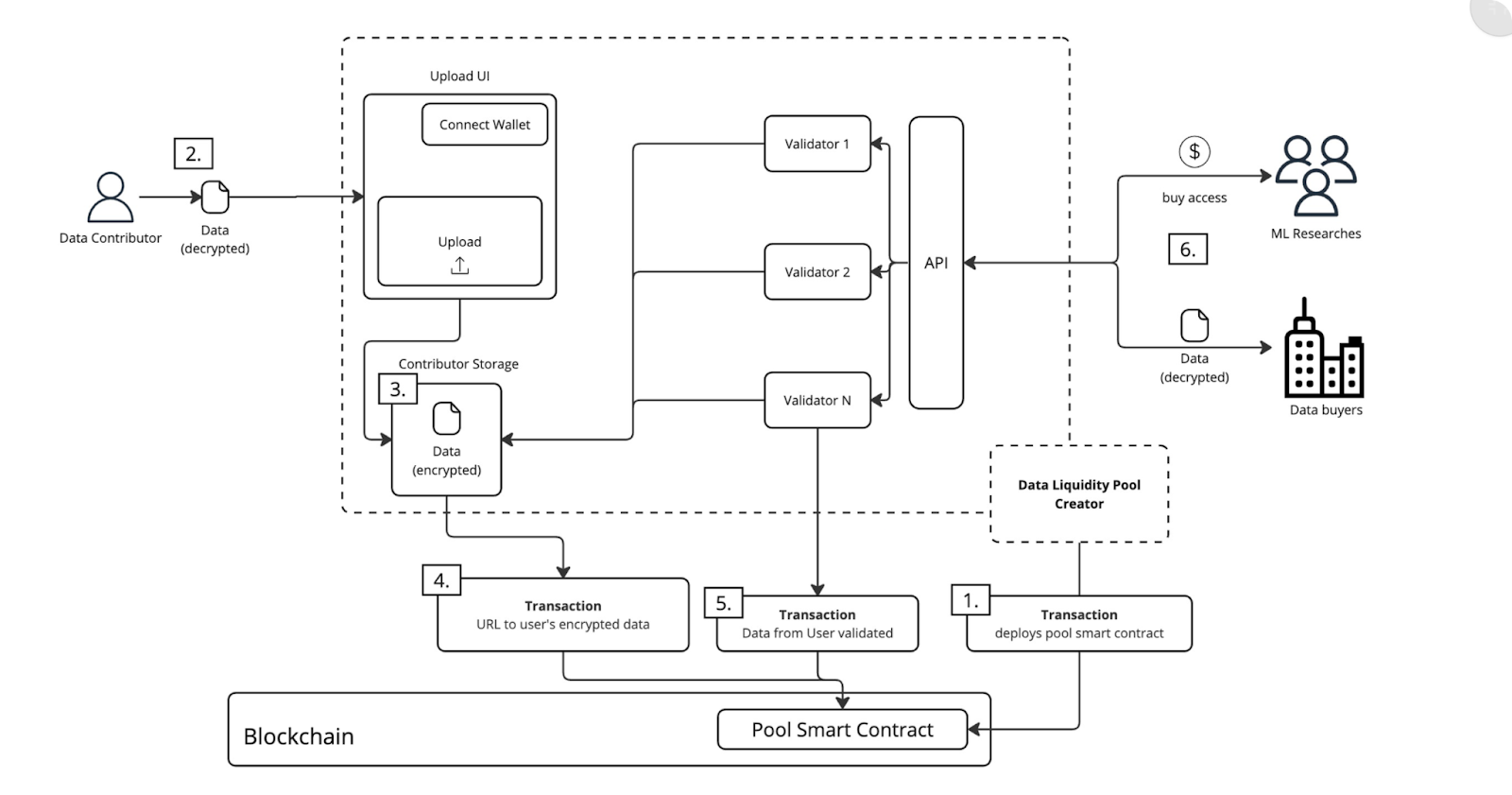
. Data Liquidity LayerLos datos aportados por los usuarios se agrupan en Data Liquidity Pools (DLPs) en la blockchain de Vana.
Los datos se envían a través de contratos inteligentes y se validan mediante el mecanismo de prueba de contribución de Vana, lo que garantiza que solo se acepten datos de alta calidad. Las diferentes DAO de datos pueden establecer sus propios parámetros de calidad para la prueba de contribución, recompensando a los contribuyentes en función del valor de sus datos, como cuánto mejoran un modelo de IA. Para incentivar aún más la calidad de los datos, Vana recompensa a los 16 mejores DLP elegidos por los poseedores de tokens VANA, que apuestan tokens en DLP que esperan que destaquen. La cantidad de tokens VANA apostados determina la clasificación del DLP. Este mecanismo fomenta la competencia entre los DLP y garantiza que los grupos de mayor calidad lleguen a la cima.
Aunque los creadores de DLP pueden establecer la estructura de recompensa inicial, la gobernanza se traslada finalmente a la comunidad. Los titulares de tokens DLP y los contribuyentes de Data DAO pueden votar sobre los cambios en el sistema de recompensas y otros aspectos operativos. Una tabla de clasificación hace un seguimiento de los mejores DLP, fomentando la transparencia y la sana competencia a medida que los recién llegados desafían a los grupos establecidos con mejor calidad de datos o más apoyo de la comunidad.
2. Capa de portabilidad de datos. Capa de Portabilidad de Datos
La Capa de Portabilidad de Datos sirve como capa de aplicación de la blockchain de Vana, permitiendo a los desarrolladores y usuarios construir dApps y modelos de IA utilizando datos agrupados.
También proporciona un mercado donde los contribuyentes se benefician del valor creado por sus datos, dependiendo de cómo la DAO decida monetizarlos. Por ejemplo, podrían recibir ingresos de un modelo de IA lanzado y gobernado por la DAO de datos o revendiendo los datos a empresas de IA.

3. Connectome
En el núcleo de la blockchain de Vana se encuentra el Connectome, un libro de contabilidad compatible con EVM que registra y valida las transacciones de datos en tiempo real, garantizando que los DAO de datos puedan funcionar en diferentes ecosistemas.
Enjoying this article?
Subscribe to Bankless or sign in
Cada transacción incluye metadatos esenciales como el tipo de datos, el formato, las propiedades, la ubicación de almacenamiento y los certificados de validez. Connectome realiza un seguimiento de las transferencias de tokens DLP, garantiza el acceso cruzado a los datos DLP y admite aplicaciones propiedad de los usuarios. Dado que también es compatible con EVM, Vana puede integrarse con otras blockchains y sus aplicaciones.
Los usuarios conservan el control total sobre sus datos y claves cifrados, pero pueden delegar la gestión en Custodios de Datos de confianza, que almacenan y protegen de forma segura los datos de los usuarios, simplificando la gestión de datos al tiempo que mantienen la privacidad.
Más transacciones en las últimas 24h en Moksha (vana testnet), que en
- Anna Kazlauskas (@anna_kazlauskas) 13 de octubre de 2024Ethereum mainnet, Sepolia, y Base Sepolia
Los datos propiedad de los usuarios se están acelerando pic.twitter.com/wabtF1tVHu
Data DAOs Building on Vana
A pesar de ser pre-mainnet, ya han surgido varias Data DAOs en fase inicial en la blockchain de Vana:
🤖 r/datadao (Reddit Data)
La DAO más grande actualmente, la r/datadao cuenta con datos de 140K usuarios de Reddit, que se han unido para entrenar el primer modelo de IA propiedad de usuarios, mostrado anteriormente, que actualmente está integrando en una característica clave de su página de inicio, y tiene la intención de lanzar con ORA como la primera Oferta Inicial de Modelos (OIM) del mundo. La DAO también ha navegado y completado una venta de sus datos a una empresa externa de IA, cuyos frutos distribuirá a los miembros.
🐦 Volara (Twitter/X Data)
Volara, una DAO de datos construida por los primeros mineros de Bittensor, se centra en Datos de Twitter/X y utiliza la blockchain de Vana para permitir a los contribuyentes poseer y monetizar su contenido de medios sociales, proporcionando a los investigadores y desarrolladores acceso a valiosos conjuntos de datos al tiempo que reduce las barreras tradicionales a la disponibilidad de datos.
👔 DLP Labs (Resume Data)
DLP Labs' Data DAO permitirá a los usuarios monetizar los datos de sus currículos, agregando datos y garantizando al mismo tiempo que los colaboradores mantengan la propiedad para construir el mayor conjunto de datos de currículos propiedad de los colaboradores.
⛈️ Syd Intel (Threat Intelligence)
Syd se centra en descentralizar el acceso a threat intelligence agregando datos de Web2, Web3 y la dark web. Los contribuyentes pueden obtener ingresos compartiendo datos de inteligencia de amenazas, como si un inversor vuelca tokens en TGE, si los enlaces son maliciosos o reales, o si los fundadores tienen un historial de proyectos fraudulentos. Todos estos datos se ponen a disposición de las empresas de seguridad y los desarrolladores en Vana.
🐷 DataPig (Trading Data)
DataPig agrega datos comerciales de las plataformas DeFi, proporcionando perspectivas personalizadas y herramientas de análisis comercial para los usuarios. La plataformautiliza IA para analizar datos, presentándolos en un formato accesible y humorístico.
🧬 DNA DAO (Genetic Data)
Surgida en respuesta a la preocupación por la posible venta de datos de usuarios por parte de 23andMe, así como a sus anteriores filtraciones, DNA DAO (antes 23andWE) busca capacitar a los individuos para reclamar y controlar sus datos genéticos con un DLP. Al contribuir a este colectivo, los usuarios salvaguardan su información genética de los intereses corporativos, garantizando que se comparte de forma ética y transparente al tiempo que tienen la opción de contribuir a la investigación.
Pensamientos finales
En general, Vana aborda uno de los mayores retos en el desarrollo de la IA: la escasez de datos.
A medida que los modelos de IA requieran conjuntos de datos más grandes y diversos, el valor de los datos generados por los usuarios crecerá. La solución de Vana, que permite a los usuarios agrupar, verificar y monetizar colectivamente sus datos, crea un nuevo paradigma sobre cómo se utilizan los datos en la IA y a quién se compensa. Las DAO de datos proporcionan simultáneamente una forma de que los usuarios recuperen el control de sus datos y compartan el valor que generan.
Aunque el futuro es incierto, Vana promete abordar los problemas a los que se enfrentan todas las partes en la IA, permitiendo un nuevo espacio de diseño que fortalece el papel de las criptomonedas como un actor clave en la economía de los datos.
La solución de Vana, que permite a los usuarios agrupar, verificar y monetizar sus datos, crea un nuevo paradigma sobre cómo se utilizan los datos en la IA y quién es compensado.




